타닥타닥14: 쇼핑몰 웹 로그 분석 본문
kaggle의 온라인 쇼핑 행동 로그 데이터를 분석하고 나온 지표들을 superset을 이용하여 시각화
온라인 쇼핑 고객 행동 로그 분석
목차
위의 목차를 클릭하면 해당 글로 자동 이동 합니다.
1. 행동 로그 데이터셋 기본 분석
캐글의 데이터 셋 중 "eCommerce behavior data from multi category store" 이름의 데이터를 다운.
그 중 "2019-Nov.csv"파일을 로드하여 분석해보자!



일단 데이터셋 자체에 대한 기본 정보들을 정리해 보았다.
아무래도 캐글에 있는 정리된 데이터셋이라 구조도 굉장히 단순하고 카테고리화도 아주 훌륭하게 되어 있다. 실제로 사용되는 로그 데이터는 이정도로 정리하기까지가 한달은 걸릴듯? 하지만 이미 잘 정리되어 있으니 잘 사용해보자.
2. 샘플을 이용한 시각화 분석
데이터 셋의 전체 크기는 67501979행으로 너무나 크기 때문에 바로 superset에 올린다면 chart나 dashboard를 편집할 때마다 너무나 긴 로딩이 필요해질 것이다. 그러니 200만행만 샘플로 추출하여 데이터에 대한 이해용 차트들을 그려보자.

Text등을 이용하여 설명하고자 하는 데이터에 대한 자세한 내용을 기술할 수 있다.
분석은 위에서 했기 때문에, 차트에 쓰이는 용어와 이 대시보드에서 선택할 수 있는 필터 조건 정도만 적어보았다.

일단 첫번째 화면을 보면 데이터가 특정 날짜에 굉장히 집중된 되어 있는 것을 볼 수 있다. 또한, 당연하게도 view는 상당히 많으나 cart에 담거나 purchase를 하는 전환율은 굉장히 낮다. 다만, cart에 담고 purchase로 전환되는 비율은 0.295 정도로 상당히 높다고 볼 수 있으니 일단 cart에 담게만 한다면 성공적이라고 할 수 있겠다.

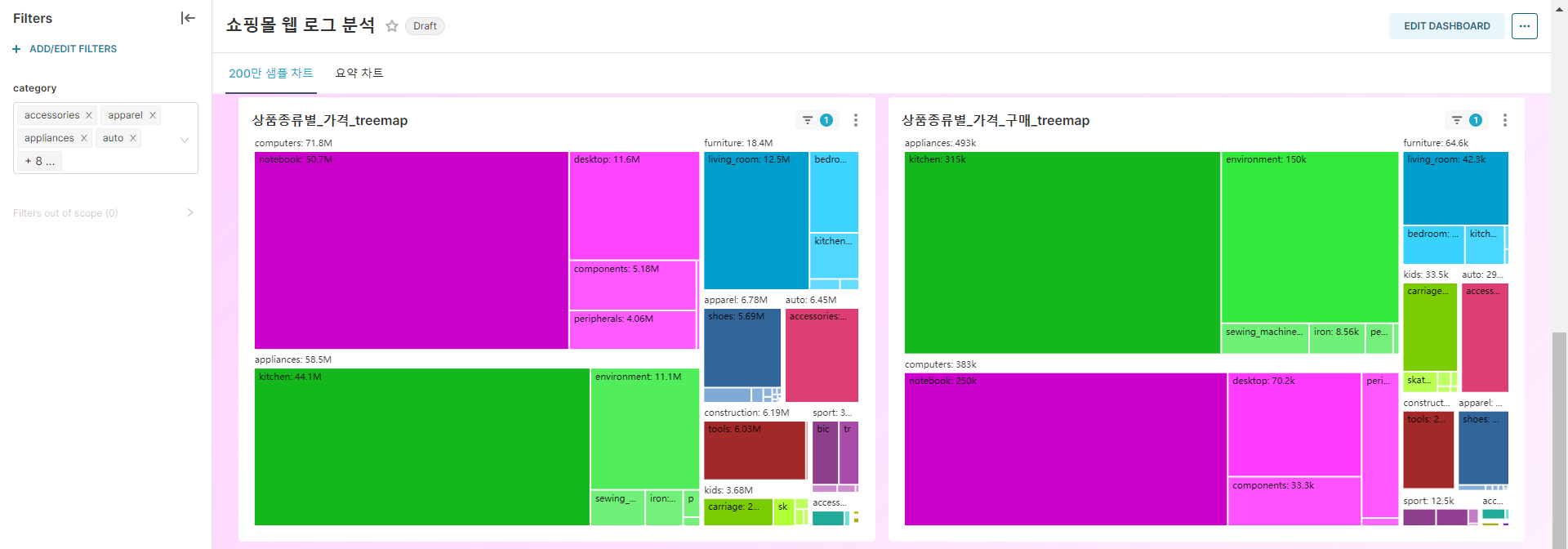
두번째 화면을 보면 상품 종류별로 어떤 것들이 주로 팔렸는지를 시각적으로 확인할 수 있다. 왼쪽의 treemap은 view/cart/purchase 전부를 나타낸 것이고, 오른쪽의 treemap은 purchase만을 나타낸 것이다. 확인히 큰 차이는 없으나 아래 항목들에선 순위가 뒤바뀐 것을 볼 수 있다. 이를 잘 보기 위해, 아래 화면에는 electronic과 null 항목을 필터링으로 제외시켰다. 모든 event_type이 들어간 treemap에서는 computer가 가장 큰 비율을 차지하지만 purchase만을 보는 treemap에선 appliance가 가장 큰 비율을 차지한다. computer의 경우는 구경하거나 카트에는 많이 담지만 구매로 이어지는 경우가 appliance보다 낮다는 것을 알 수 있다.

마지막 화면의 위쪽의 pivot 차트에서는 각 카테고리와 서브카테고리별 날짜기준 구매를 볼 수 있다. 필터를 걸어가며 보고자 하는 날짜 등을 자세하게 확인해볼 수 있다.
아래쪽의 calender와 bar 차트를 보면, 데이터셋의 배경이나 상황은 알 수 없지만 데이터의 분포와 공백을 보건데, 11월 15일에는 뭔가 구매가 안되는 기능 장애 같은 상황이 있었을 것 같고, 그 뒤에 뭔가 혜택이 있어서 사람들이 왕창 구매한 것이 아닐까 싶다. bar에서는 특정 날짜가 빈 것만을 확인할 수 있지만, calender와 같은 차트로 보면 시간 단위, 분단위, 초단위까지 구분하여 데이터를 살펴볼 수 있으니 굉장히 상세한 분석이 가능하다.
구매가 전혀 없는 15일 새벽 4시부터 16일 오후 4시까지 무슨 일이 있었던 걸까?
17일 새벽 1시부터 12시까지도 구매 내역이 없네...?
분단위로 보았을 때 구매 빈도 등이 굉장히 비정상적으로 없었다가 몰리고 있는 것이 시각화 된다.
이렇게 superset을 이용한다면 분석하고 있는 데이터를 시각적으로 직관화해서 확인할 수 있다. pandas나 numpy의 기능들을 통해서도 분석은 가능하겠지만 시각적으로 확인하는건 확실히 다르다. 데이터셋을 올리고 차트로 변환하는데 10분 안쪽이면 충분하니 새로운 데이터에 대한 전반적인 이해도를 높이는데에 superset 적극 활용해보자.
3. 데이터 정리 및 요약
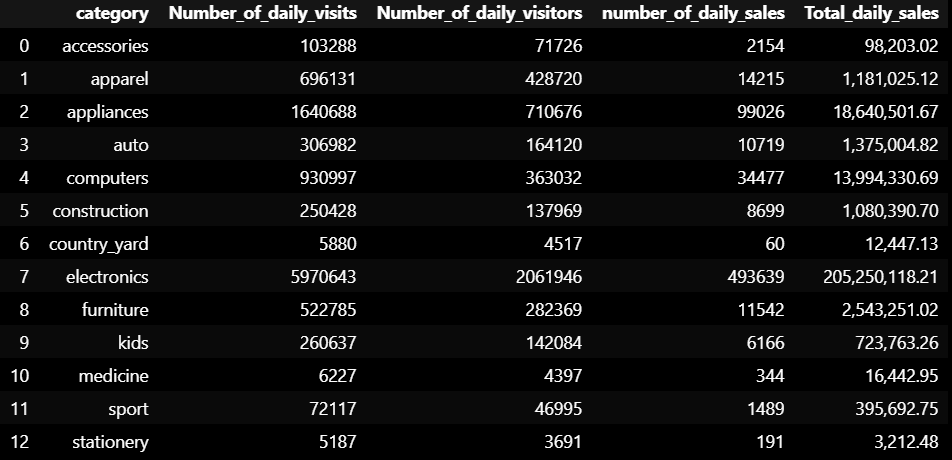
데이터를 일별, 브랜드별, 카테고리 별로 aggregation 집계.
 |
 |
 |
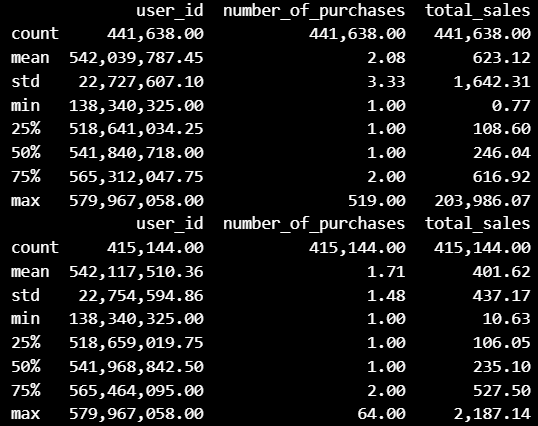
상품 구매 횟수에 따른 고객 비율, 극값을 제거한 plot확인, 상위 10퍼센트의 우량고객 리스트.
 |
 |
 |
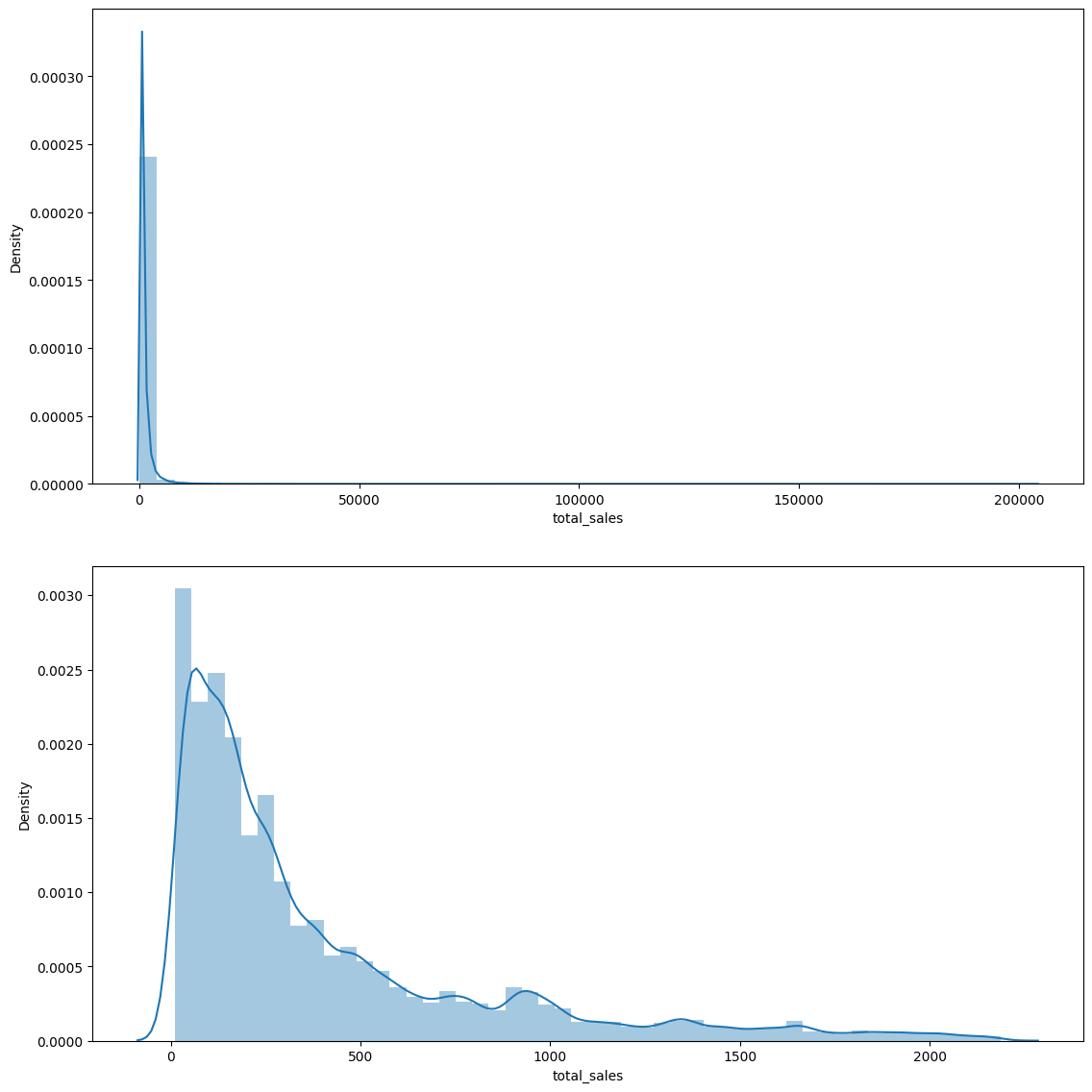
이렇게 정리한 데이터를 토대로 요약 대시보드를 그려보자.
4. 요약 데이터 시각화
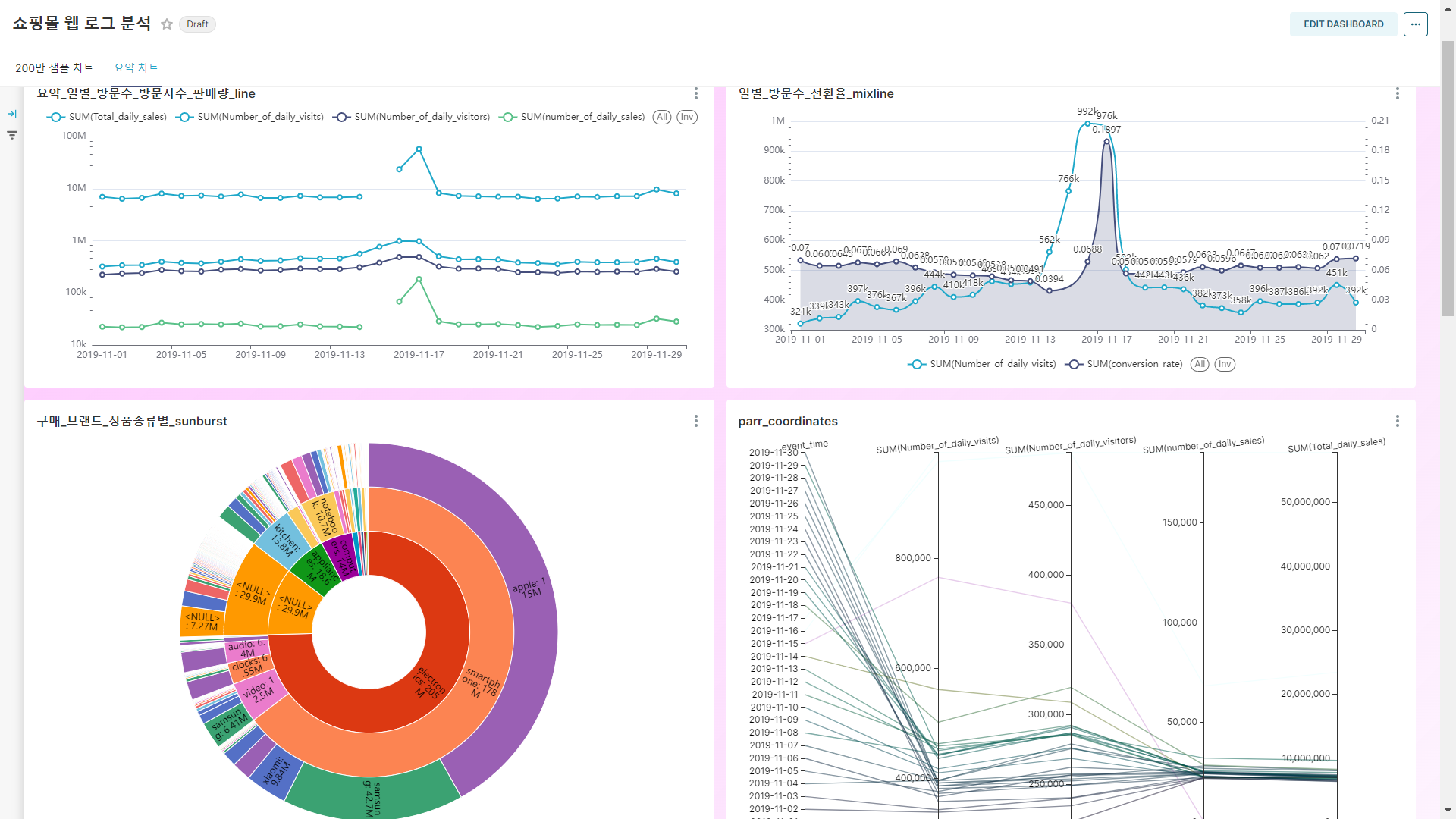

데이터 셋을 정리하여 보고자 하는 지표나 방식대로 정리한 이후 superset을 이용하여 간단하게 시각화 해보았다. 다음에는 이와 같이 정리된 데이터를 이용하여 ML 모델링을 하고 결과를 superset을 이용하여 나타내 볼 예정.
데이터를 분석하는 방식으로의 대시보드와 요약된 데이터를 나타내는 대시보드를 생성해 보았다. Superset은 데이터를 분석하는 단계에서는 여러가지 방향으로 접근해 볼 수 있기에 데이터를 다양한 관점에서 들여다 보는데 큰 도움이 된다. 또한, 정리한 데이터를 단순 집계형 테이블로 보여주는 것이 아니라 직관적인 차트 형태로의 변환이 가능하기에 결과를 공유하기에 굉장히 좋은 수단이 된다.
추천글
'공부' 카테고리의 다른 글
| 타닥타닥16: Superset User&Role (0) | 2023.06.20 |
|---|---|
| 타닥타닥15: AWS EC2 Superset 설치 (0) | 2023.06.12 |
| 타닥타닥13: Superset 설정 이모저모 (0) | 2023.05.30 |
| 타닥타닥12: Superset Chart 및 Dashboard 구성 (0) | 2023.05.23 |
| 타닥타닥11: Superset(데이터시각화 도구) 오프라인 설치 (0) | 2023.05.11 |



