타닥타닥10: logloss란? 본문
Logloss란?
분류 모델을 평가하는데 사용하는 모델 성능 평가 지표
이진 분류, 다중 분류, 다중 레이블 분류 모델에서 모두 사용될 수 있다.
교차 엔트로피 손실(Cross-entropy loss) 또는 로지스틱 손실(Logistic loss)로도 알려져 있다.
사용하는 이유는?
최종적으로 맞춘 결과만을 가지고 성능을 평가할 경우, 어느 정도의 확률로 해당 답을 얻은 것인지에 대한 평가는 불가능하다. 답을 맞추더라도 낮은 확률로 우연히 얻어 걸린 것이라면 성능이 좋은 모델이라고 평할 수 없을 것이다.
이를 보완하기 위해서는 확률 값을 평가 지표로 사용하면 되는데, Logloss는 모델이 예측한 확률 값을 직접적으로 반영하여 평가한다.
아래 식을 보면 확률 값을 음의 log함수에 넣어 변환을 시킨 값으로 평가하는데, 이는 잘못 예측할때 패널티를 부여하기 위함이다. 그렇기에 낮을수록 좋은 지표이며, 이를 낮추는 방식으로 학습을 진행시킨다.

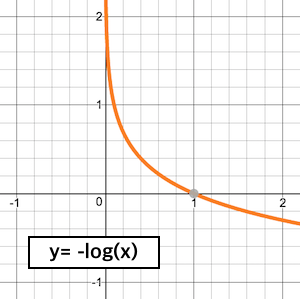
예를 들어, 100% 확률로 예측한 답의 경우는 -log(1.0) = 0 이다. 80% 확률이라면 -log(0.8) = 0.22 이다. 이런식으로 확률이 낮을수록 logloss의 값이 빠르게 증가하게 된다.
예제코드
import numpy as np
def log_loss(y_true, y_pred):
assert len(y_true) == len(y_pred), "Lengths of true labels and predicted probabilities must be equal."
n_samples = len(y_true)
log_loss_value = -np.sum(y_true * np.log(y_pred) + (1 - y_true) * np.log(1 - y_pred)) / n_samples
return log_loss_value
# 샘플 데이터
y_true = np.array([1, 0, 1, 1, 0, 1])
y_pred = np.array([0.9, 0.1, 0.8, 0.7, 0.2, 0.6])
# 로그 손실 계산
loss_value = log_loss(y_true, y_pred)
print("Log loss:", loss_value)
> Log loss: 0.2540847836081325
from sklearn.metrics import log_loss
import numpy as np
# 실제 클래스 레이블과 모델이 예측한 클래스 레이블의 확률값
y_true = np.array([0, 1, 1, 0])
y_pred = np.array([[0.9, 0.1], [0.4, 0.6], [0.7, 0.3], [0.2, 0.8]])
# logloss 계산
logloss = log_loss(y_true, y_pred)
print("Logloss: ", logloss)
> Logloss: 0.8573992140459634
기초적인 것부터 하나하나 제대로 채워나가야 한다는 것을 실감하는 요즘.
'공부' 카테고리의 다른 글
| 타닥타닥12: Superset Chart 및 Dashboard 구성 (0) | 2023.05.23 |
|---|---|
| 타닥타닥11: Superset(데이터시각화 도구) 오프라인 설치 (0) | 2023.05.11 |
| 타닥타닥9: Decision Tree Model (0) | 2023.05.01 |
| 마케팅, 추천시스템 (영어 기사 한글 정리) (0) | 2023.03.06 |
| 타닥타닥8: 협업 필터링(Collaborative Filtering, CF) 알고리즘 (0) | 2022.12.05 |
'공부' 관련글
더보기




Comments